
Data is invaluable in today’s world, whether integrated for individual or commercial purposes. However, many times, we fail to collect high-quality and adequate amounts of data. As a result, we fail to accomplish our desired goals. Synthetic data generation can address such situations and fix the scarcity of data for model training, research, software testing, and other occasions. But what opportunities can synthetic data generation using GANs offer? Let’s find out...
Synthetic data generation is a prevailing practice, especially for analytics and AI projects. As per sources, 60% of such projects used synthetic data in 2024. Experts note that the global industry of synthetic data generation recorded a valuation of $310 million in 2024, which is expected to surpass $6 billion by 2034.
In this blog, we’ll understand how using generative adversarial networks (GANs) can be beneficial for synthetic data generation. Let us understand both elements separately first.
What is Synthetic Data Generation?
Synthetic data refers to artificial information that replicates real-world data, mimicking statistical aspects and structure. The usage of different algorithms and models contributes to the identification and replication of features, patterns, and relations within real-world datasets. Following that, simulation helps in generating structured and unstructured synthetic data.
Developers and researchers commonly utilize artificial or synthetic data to train AI and machine learning algorithms. Such procedures require a significant quantity of data, which is often difficult to collect due to data scarcity. Synthetic data fills the data gap, assisting developers in designing models based on real-world data. Furthermore, such an approach assists in securing the privacy of individuals by eliminating sensitive information from datasets while training machine learning models.
What Are GANs?
Generative adversarial networks, or GANs, refer to a machine learning architecture that operates based on deep learning algorithms. The major components of GANs include two neural networks: a generator and a discriminator. Both networks compete with each other to process data and make predictions. Therefore, synthetic data generation using GANs can be highly beneficial.
GANs usually have three segments: generative, adversarial, and networks. Generative denotes the process of generating data based on a stochastic model. Conversely, the adversarial phase ensures training a model in an antagonistic atmosphere. Lastly, deep neural networks work as algorithms that help in the training process.
How Should We Initiate Synthetic Data Generation Using GANs?
Generative adversarial networks are nothing but a generative model that uses deep learning algorithms. It includes two sub-models that collaboratively contribute to synthetic or artificial data generation.
The functionality of synthetic data generation using GANs begins with data input to the generator and the generated data processed through the discriminator.
For example, if a real-world image of a cat is fed to the generator and asked to create the closest outcome, the generator will use neural networks to identify the patterns and features in the image and try to replicate the input. The initial results may have minimal similarities with the real-world data.
The outcome will then be forwarded to the discriminator. Following the overview of the outcome, the discriminator assesses the similarities with the raw image, tracing the dissimilarities. Until the dissimilarities are addressed, the operation continues between the generator and the discriminator. The ultimate outcome generated by the generator and approved by the discriminator can be used as synthetic data.
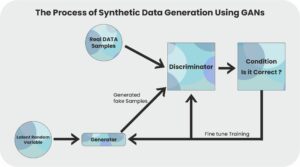
The above-displayed visual representation depicts how GANs work.
Synthetic data generation using GANs can be advantageous in many ways. The generated information mimics real-world insights but doesn’t include its sensitivity.
How to Generate Synthetic Data with GANs?
Primarily, developers define the outcome that they want and collect initial datasets accordingly. The data is then fed to the generator, which proceeds with outcome generation with minimal accuracy. The discriminator afterward finds similarities between the generated and actual data, rejecting adversaries between the two.
The process continues until the time the generator produces the closest to the expected results. Here, using pytorch can simplify the entire activity. Below is an example on how to generate synthetic data using GANs with pytorch as depicted by towards data science-
Understanding how the Generator and Discriminator of the GAN model Function:
import torch
from torch import nn
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn.init as init
import pandas as pd
import numpy as np
from torch.utils.data import Dataset
# defining a single generation block function
def FC_Layer_blockGen(input_dim, output_dim): single_block = nn.Sequential( nn.Linear(input_dim, output_dim),
nn.ReLU()
)
return single_block
# DEFINING THE GENERATOR
class Generator(nn.Module):
def __init__(self, latent_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, output_dim),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
#defining a single discriminattor block
def FC_Layer_BlockDisc(input_dim, output_dim):
return nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.Dropout(0.4)
)
# Defining the discriminator
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
#Defining training parameters
batch_size = 128
num_epochs = 500
lr = 0.0002
num_features = 6
latent_dim = 20
# MODEL INITIALIZATION
generator = Generator(noise_dim, num_features)
discriminator = Discriminator(num_features)
# LOSS FUNCTION AND OPTIMIZERS
criterion = nn.BCELoss()
gen_optimizer = torch.optim.Adam(generator.parameters(), lr=lr)
disc_optimizer = torch.optim.Adam(discriminator.parameters(), lr=lr)
Data Integration and Model Initialization:
# IMPORTING DATA
file_path = 'SamplingData7.xlsx'
data = pd.read_excel(file_path)
X = data.values
X_normalized = torch.FloatTensor((X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) * 2 - 1)
real_data = X_normalized
#Creating a dataset
class MyDataset(Dataset): def__init__(self,dataframe): self.data=dataframe.values.astype(float)
self.labels = dataframe.values.astype(float)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = {
'input': torch.tensor(self.data[idx]),
'label': torch.tensor(self.labels[idx])
}
return sample
# Create an instance of the dataset
dataset = MyDataset(data)
# Create DataLoader
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
def weights_init(m):
if isinstance(m, nn.Linear):
init.xavier_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
pretrained = False
if pretrained:
pre_dict = torch.load('pretrained_model.pth')
generator.load_state_dict(pre_dict['generator'])
discriminator.load_state_dict(pre_dict['discriminator'])
else:
# Apply weight initialization
generator = generator.apply(weights_init)
discriminator = discriminator.apply(weights_init)
Training Model:
model_save_freq = 100
latent_dim =20
for epoch in range(num_epochs):
for batch in dataloader:
real_data_batch = batch['input']
# Train discriminator on real data
real_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1)))
disc_optimizer.zero_grad()
output_real = discriminator(real_data_batch)
loss_real = criterion(output_real, real_labels)
loss_real.backward()
# Train discriminator on generated data
fake_labels = torch.FloatTensor(np.random.uniform(0, 0.1, (batch_size, 1)))
noise = torch.FloatTensor(np.random.normal(0, 1, (batch_size, latent_dim)))
generated_data = generator(noise)
output_fake = discriminator(generated_data.detach())
loss_fake = criterion(output_fake, fake_labels)
loss_fake.backward()
disc_optimizer.step()
# Train generator
valid_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1)))
gen_optimizer.zero_grad()
output_g = discriminator(generated_data)
loss_g = criterion(output_g, valid_labels)
loss_g.backward()
gen_optimizer.step()
# Print progress
print(f"Epoch {epoch}, D Loss Real: {loss_real.item()}, D Loss Fake: {loss_fake.item()}, G Loss: {loss_g.item()}")
Assessing the Outcomes:
import seaborn as sns
# Generate Synthetic Data
synthetic_data = generator(torch.FloatTensor(np.random.normal(0, 1, (real_data.shape[0], noise_dim))))
# Plot the results
fig, axs = plt.subplots(2, 3, figsize=(12, 8))
fig.suptitle('Real and Synthetic Data Distributions', fontsize=16)for i in range(2):
for j in range(3):
sns.histplot(synthetic_data[:, i * 3 + j].detach().numpy(), bins=50, alpha=0.5, label='Synthetic Data', ax=axs[i, j], color='blue')
sns.histplot(real_data[:, i * 3 + j].numpy(), bins=50, alpha=0.5, label='Real Data', ax=axs[i, j], color='orange')
axs[i, j].set_title(f'Parameter {i * 3 + j + 1}', fontsize=12)
axs[i, j].set_xlabel('Value')
axs[i, j].set_ylabel('Frequency')
axs[i, j].legend()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
# Create a 2x3 grid of subplots
fig, axs = plt.subplots(2, 3, figsize=(15, 10))
fig.suptitle('Comparison of Real and Synthetic Data', fontsize=16)
# Define parameter names
param_names = ['Parameter 1', 'Parameter 2', 'Parameter 3', 'Parameter 4', 'Parameter 5', 'Parameter 6']
# Scatter plots for each parameter
for i in range(2):
for j in range(3):
param_index = i * 3 + j
sns.scatterplot(real_data[:, 0].numpy(), real_data[:, param_index].numpy(), label='Real Data', alpha=0.5, ax=axs[i, j])
sns.scatterplot(synthetic_data[:, 0].detach().numpy(), synthetic_data[:, param_index].detach().numpy(), label='Generated Data', alpha=0.5, ax=axs[i, j])
axs[i, j].set_title(param_names[param_index], fontsize=12)
axs[i, j].set_xlabel(f'Real Data - {param_names[param_index]}')
axs[i, j].set_ylabel(f'Real Data - {param_names[param_index]}')
axs[i, j].legend()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
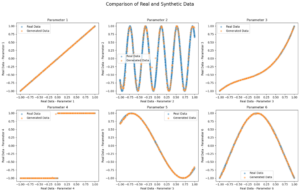
As per toward data science, the above-depicted visuals represent the comparison between real-world and synthetic data generated through GANs with pytorch.
Use cases of Synthetic Data Generated using GANs:
Natural Language Processing: With synthetic text generated with GANs, machine learning models can be trained for natural language processing, including translations, summarizations, and others.
Fraud Detection: Synthetic data generation using GANs that mimic real-world situations of fraud and cyber-attacks can be used to train machine learning models for anomaly detection, preventing fraud.
Medical and healthcare purposes: GANs’ synthetic data can be utilized by the medical field in training models for treatment predictions and planning.
Image and Vision Processing: Synthetic images and 3D models generated by GANs can contribute to training ML models for image classification and even for text-to-image algorithms.
Ethical Concerns of Synthetic Data Usage:
Synthetic data generation and usage can impose significant ethical concerns, such as:
Data Accuracy: Synthetic data replicates real-world data but seldom includes accurate insights. Since the dependency on ML models is increasing and such models can be trained on inaccurate data, the consequences can also be misleading.
Incomplete data: Synthetic datasets often have incomplete information, alongside errors and misleading insights. Due to this, machine learning models cannot be trained appropriately.
Inconsistency: Authentic data are extracted from real-world events and multiple reliable sources. On the other synthetic data only mimics real data. Therefore, the latter cannot match the consistency parameters of the former.
GANs to Redefine a New Era in Synthetic Data Generation!
Synthetic data has doubtlessly contributed to AI advancements. Based on synthetic data, most of the AI and ML models are trained. Such datasets enable developers to attain enough information to train their models at significantly low cost. Synthetic data generation using GANs can be highly impactful as the latter helps replicate real-world data in the best way possible.
There are various types of GANs, including Vanilla GAN and Conditional GAN, which are integrated as per the predefined desired outcome. Hence, it is suggested that you choose a GAN framework that resembles your expected results and type of data.
Visit KnowledgeNile and explore our other informative blogs on the latest technology!
Recommended For You:


