Apache Kafka and RabbitMQ are two of the most widely used pub-sub platforms. These platforms help data scientists to utilize the pull/push notifications effectively.
They are also used to perform complex data operations for Big Data. We will be discussing the key factors that differentiate the Apache Kafka and RabbitMQ through this blog.
Apache Kafka Vs. RabbitMQ: Top 9 Differentiating Factors
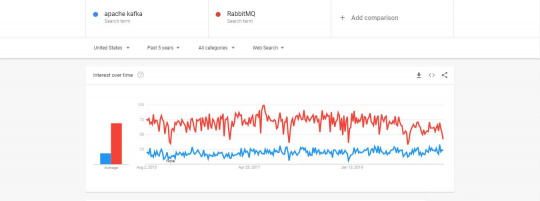
We can observe from the above mentioned Google Trends graph that RabbitMQ is more popular than Apache Kafka.
This graph shows the search results over the last five years in the United States. We can also see that there are a few periods where the search popularity for the RabbitMQ has dipped.
But even then, it has managed to be more popular than Apache Kafka.
Apache Kafka is open-source, and it is a more recent tool, and it is a message broker platform that can process and reprocess the datasets. It is known for its fault-tolerant nature.
On the other hand, RabbitMQ is also an open-source tool, but it is an older tool than Apache Kafka. It is a message broker platform that allows the distributed deployment. It also supports multiple messaging protocols.
Apache Kafka uses the partition approach, and it allows its users to request messages in batches from a single node point. It allows the users to distribute the messages in bulk and achieve higher throughput. And hence Apache Kafka is known as the Pull-model.
But, RabbitMQ uses a different approach by pre-limiting the number of requests. In turn, it ensures precise distribution.
This functionality allows its users to ensure individual distribution and effective message queuing. In short, it pushes the notifications to its users on the basis of the received requests. And hence RabbitMq is known as the push-model.
This is one of the most important factors that differentiate Apache Kafka and RabbitMQ.
Apache Kafka Features:
- Apache Kafka allows its users with functionality to notify messages with topic orders.
- As Apache Kafka is a log, you can easily restore the messages and the backup.
- It uses the geo-replication feature that allows message replications across the cloud and datacenters.
- As it works on the partition principle, it allows a fault-tolerant capability. For example, each partition has a leader and followers. And all the followers replicate the actions of a leader. And, if the leader fails, one of the followers takes its place and ensures a smooth working.
- Apache Kafka allows multi-tenancy by configuring and allocating the roles and quotas.
RabbitMQ Features:
- RabbitMQ follows a cluster approach and forms a single broker.
- RabbitMQ offers high availability and greater flexibility.
- It also allows a flexible routing system that allows effective queuing. You can customize routing for complex operations.
- It supports multiple languages and uses a multi-protocol approach.
Apache Kafka uses a sequential Disk/IO approach and offers high throughput. This leads to higher performance than RabbitMQ.
The high throughput enables Apache Kafka to process millions of messages per second, even with limited resources.
In comparison, RabbitMQ performs little less than Apache Kafka. Even though RabbitMQ is capable of processing millions of messages per second, you need to have higher resources for that. It has a less throughput compared to Apache Kafka.
Apache Kafka is more scalable than RabbitMQ, but RabbitMQ is more flexible than Apache Kafka, and it has higher availability.
The key applications of Apache Kafka include complex routing, event sourcing, sequential events, and multi-stage pipelining.
Its other applications also include partition ordering, real-time data flows, and tasks requiring stream backups.
On the other hand, the key applications of RabbitMQ include the applications with quick response time, legacy protocols, and a granular approach.
Its other applications include the applications that require a multi-routing approach and multi-protocol approaches.
Also Read: Confluent Kafka vs. Apache Kafka: What's the Difference?
A lot of big companies use Apache Kafka. These include Uber, Spotify, Slack, Shopify, and The New York Times, etc. to name a few.
Similarly, RabbitMQ is also deployed by some of the biggest companies around the world. These companies include Reddit, Accenture, T-Mobile, Runtastic, Trivago, and Fiverr, etc. among others.
Both Apache Kafka and RabbitMQ are open-source, free of cost tools for individual uses. But for commercial uses, you may need to pay subscription fees.
These subscription fees vary with your use and requirements. Hence for a detailed quote, you will need to visit the website.
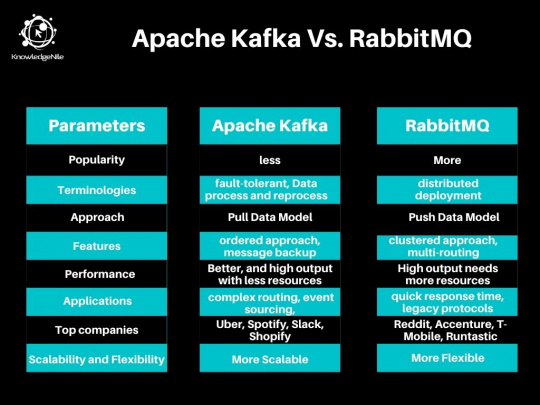
Apache Kafka vs. RabbitMQ: Tabular Comparison
Key Takeaways
Both Apache Kafka and RabbitMQ are two of the most widely used pub-sub platforms, but there are telling differences between the two.
These differences include terminologies, approach, applications, performance, and features, etc.
While you cannot say that one tool is better than another, each tool's suitability for respective requirements should decide the use of a particular tool.
Also Read: Apache Kafka vs. JMS: Difference Explained